

La extracción de datos para el mantenimiento predictivo
Proyecto SIMBA
El mantenimiento predictivo comenzó a definirse en la década de los ’80, basándose en la realización de mediciones puntuales sobre algunas variables de funcionamiento de las máquinas que podrían influir en la aparición de futuras averías. Variables como temperatura de elementos críticos, vibraciones en partes móviles, degradación de lubricantes y otras, se medían puntualmente para vigilar su evolución y detectar, en su caso, signos de desgaste de partes importantes de la máquina.
Aunque la monitorización en continuo de procesos de fabricación se utiliza desde hace décadas, el advenimiento del Internet de las Cosas (IoT) parece que ha dado un nuevo impulso a este tipo de tecnologías, reduciendo considerablemente el coste del equipamiento necesario para ello, y facilitando la deslocalización del análisis de los datos recogidos. Quizás sea esta parte, el análisis de datos, la que más rápidamente ha evolucionado en los últimos años pasando a formar parte de las tecnologías clave para la implementación de la Industria 4.0, especialmente las técnicas conocidas como Machine Learning.
Se conoce como aprendizaje automático o más conocido por el término anglosajón Machine Learning al conjunto de técnicas existentes en el ámbito de la inteligencia artificial que tienen como fin conseguir que los ordenadores sean capaces de aprender de la experiencia. Las diversas técnicas se pueden agrupar en tres conjuntos llamados aprendizaje supervisado, aprendizaje no supervisado y aprendizaje por refuerzo[1].
El aprendizaje supervisado tiene como objetivo que los algoritmos aprendan de un conjunto de datos en los que se especifica explícitamente qué es lo que deben aprender. Una vez entrenados, habrán generado un modelo que permite deducir las propiedades que se hayan aprendido de ejemplos nuevos que estén sin indicar. Estos algoritmos se pueden separar a su vez en algoritmos de clasificación y regresión.
En caso de que los diversos datos estén separados en clases y se le pida al ordenador que aprenda a diferenciar una clase de la otra, estaremos ante un algoritmo de clasificación. Los más conocidos son el método de mínimos cuadrados (LS), el análisis del discriminante lineal (LDA), las máquinas de vectores soporte (SVM), las redes neuronales artificiales (ANN), el clasificador de k vecinos más cercanos (KNN) o los árboles de decisión. La Figura 1 muestra las barreras aprendidas en un conjunto de entrenamiento dividido en tres clases.
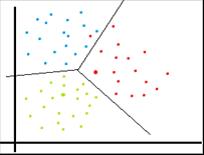
Este tipo de algoritmo es el que, probablemente, se utilizará para analizar los datos que se recogen durante el funcionamiento de la máquina e intentar predecir algún tipo de suceso que desencadenará una avería.
En el marco del proyecto SIMBA (Sistema inteligente de mantenimiento basado en el estado real del equipo) se ha completado la instalación de sensores en dos de las prensas de fabricación de la empresa KAMAX, los cuales permiten extraer datos relevantes en diferentes puntos de las máquinas considerados sensibles por el personal de mantenimiento.
Estos datos recogen valores de temperatura, vibración, sonido y consumo eléctrico. Los datos de esfuerzo en el proceso de estampación los recoge la propia máquina.

En algunos casos, las señales eléctricas procedentes de los sensores han requerido un procesamiento previo a su volcado en base de datos.
Por ejemplo, las señales de los acelerómetros triaxiales requieren, además de ser amplificadas, reducir su dimensión de forma considerable.
Un acelerómetro puede generar miles de datos por segundo, una cantidad inmanejable, por lo que deben aplicarse funciones matemáticas que reduzcan su dimensión y aporten valores realmente significativos.
Esto se consigue mediante transformadas de Fourier, que permiten obtener el valor de frecuencia y magnitud de los diez primeros armónicos (20 datos), una cantidad más que razonable. El análisis de estos armónicos ya permite establecer patrones de vibración.
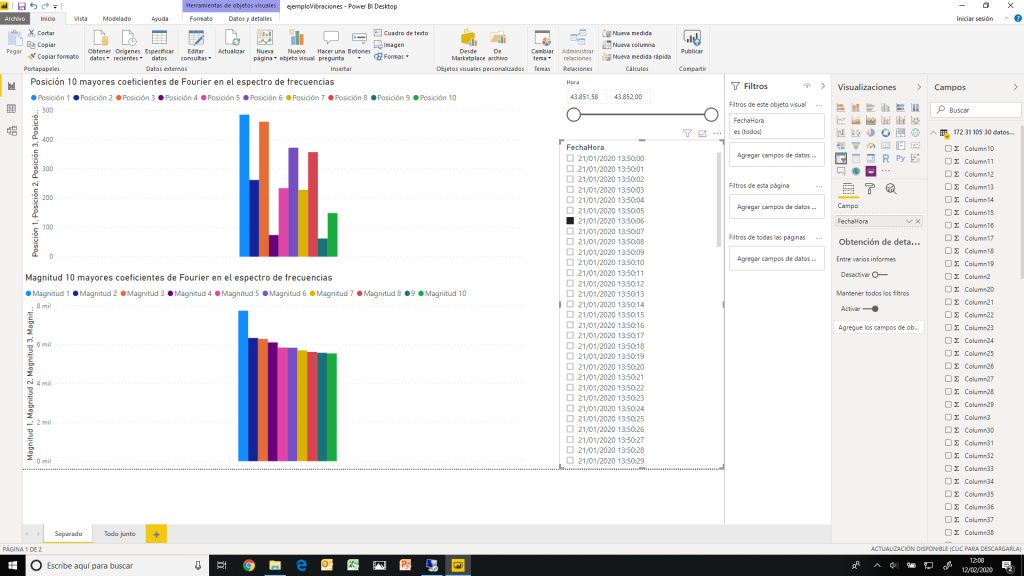
En la figura 3 puede apreciarse, para un instante de tiempo dado, la representación gráfica del valor de vibración en un eje de uno de los acelerómetros. En la parte superior aparece la posición de los diez primeros coeficientes de Fourier en el espectro de frecuencias y en la inferior la magnitud de cada uno de ellos. Aunque estos valores no tienen una fácil interpretación, su evolución en el tiempo da la información que necesita el tipo de algoritmo a desarrollar para intentar predecir futuras fallas, obviamente junto con numerosos valores de otras variables medidas.
Una vez finalice el proyecto, AIDIMME lanzará una nueva línea de servicio tecnológico para colaborar con las empresas de la Comunidad Valenciana en su estrategia de digitalización mediante el uso de los elementos desarrollados en SIMBA.
El proyecto SIMBA está enmarcado en la línea estratégica que AIDIMME lleva desplegando desde hace varios años en el ámbito de la industria 4.0, tanto en lo que se refiere a la estrategia de digitalización de las empresas (PLASMA, ACTIVA INDUSTRIA 4.0, HABITAT 4.0), la captación y análisis de datos (SAIN4, ENERGÍA INDUSTRIAL 4.0) y el mantenimiento predictivo (SIMBA).
[1] Bishop, C. M. (2006). Pattern recognition and Machine Learning. Cambridge, UK: Springer.
El proyecto está financiado por el IVACE con fondos FEDER, y en él participan las empresas KAMAX y FACTOR en las que se instalan los prototipos desarrollados.
Más información:
Otras noticias publicadas del proyecto SIMBA:
| Jose L. Sánchez Asins |
| TECNOLOGÍAS Y PROCESOS |