

Tratamiento de datos para mantenimiento predictivo
| SIMBA- SISTEMA INTELIGENTE DE MANTENIMIENTO BASADO EN EL ESTADO REAL DEL EQUIPO. IMDEEA/2019/8 – 2019-07-01 – 2020-06-30 |
El objetivo final del proyecto es desarrollar un sistema inteligente de análisis del funcionamiento de dos clases determinadas de máquinas (prensas de estampación y tornos automáticos), basándose en la información en tiempo real facilitada por un conjunto de sensores que miden diversas variables de los equipos. Este sistema inteligente, ubicado en una plataforma ad-hoc, será accesible a cualquier empresa del sector que siga los protocolos de medición definidos previamente, y los resultados de las predicciones podrán ser visualizados de forma continua por cada empresa usuaria.

Tras la instalación de los sistemas de captura de datos en dos prensas y en un torno de decoletaje en el marco del proyecto SIMBA (Sistema inteligente de mantenimiento basado en el estado real del equipo) se ha comenzado el análisis de los datos recogidos de forma independiente, sin relacionarlos aún con las incidencias reales que hayan podido aparecer durante el periodo de la toma de datos.
Los dispositivos para la toma de datos se han diseñado de forma que cada uno de ellos se encarga de recoger datos de un acelerómetro triaxial, un micrófono, cuatro sondas de temperatura y cuatro sensores de consumo eléctrico. La imagen muestra dos de los dispositivos utilizados.
Preparación de datos
Los datos recopilados en la empresa donde están instaladas las prensas (KAMAX) suponen un dato tomado de forma continua cada segundo durante casi 3 meses, y a través de 4 dispositivos de recolección distinto, amasando un total de 7 GB de datos, lo que hace a este conjunto de datos excesivamente grande para su tratamiento en equipos convencionales. Para simplificar este tratamiento se han seguido los pasos indicados a continuación.
En primer lugar se ha procedido a eliminar datos de los periodos de inactividad (periodos festivos y paradas por mantenimiento). Para esto se ha hecho uso de la biblioteca de tratamiento y manipulación de datos PANDAS para Python.
Seguidamente se ha procedido a reducir la cantidad de variables de las cuales se dispone información, para lo cual se utilizan métodos de reducción de dimensionalidad basados en el análisis de componentes principales, abreviado comúnmente como PCA por su nombre en inglés. Este algoritmo se puede encontrar en la librería de Python SKLEARN.
En un primer paso se normalizan los datos, lo cual asegura que todas las variables se encuentran en la misma escala, lo que permite al algoritmo de PCA entender la importancia real que refleja cada subespacio independientemente del tamaño de los datos que se encuentren ahí.
El segundo paso es averiguar a cuantas dimensiones se pueden reducir los datos sin perder una gran cantidad de información. En particular, se establece el criterio de mantener el 95% de la misma. Para ello se ajusta el algoritmo a los datos de entrada y se pide que muestre el porcentaje de información que se puede mantener seleccionando cada posible cantidad de dimensiones. Para esto, el PCA utiliza la descomposición en valores singulares (SVD) y muestra el porcentaje que representa cada uno sobre el total. El resultado es el mostrado en la figura siguiente, donde en el eje vertical se puede leer el nivel de significación de los datos (1 = 100%) y en el horizontal el número de variables al cual se reducen todos los datos.
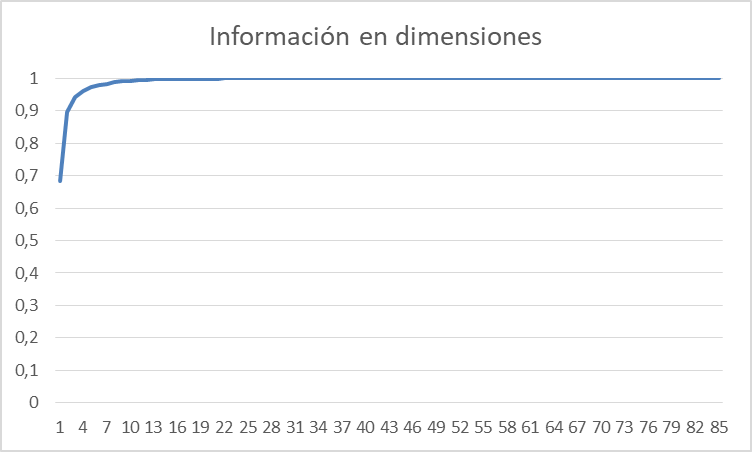
En la figura 2 se puede apreciar que, a partir de 4 dimensiones, se mantiene el 95% de toda la información disponible, por lo que se puede hacer hacer que PCA transforme los datos en un subespacio de dimensión 4. Mediante estas transformaciones para 1 archivo, se reduce su tamaño de 2.113MB a apenas 319MB suponiendo una disminución del 84,91%, lo cual ya permite trabajar con estos datos. La reducción de dimensionalidad de 48 variables originales a 4 variables finales facilita enormemente su tratamiento, aunque estas variables finales no tienen un significado físico real, lo cual puede dificultar la interpretación de las mismas en caso de que esto fuese necesario.
Agrupación y búsqueda de patrones
Seguidamente se utilizaron algoritmos de aprendizaje no supervisado capaces de encontrar los patrones que forman los datos, de manera que permitan identificar estados dentro del conjunto de datos. Para ello se utiliza el algoritmo de K-medias, conocido como Kmeans.
Kmeans permite encontrar agrupaciones que existan en los datos. Se debe decidir el número K de agrupaciones (clusters) que se quiere buscar. Como a priori este dato es desconocido, se va a obtener el que resulte óptimo. Existen varios métodos para buscar la idoneidad de cada uno de los valores, siendo el más conocido el método de la silueta. Sin embargo, el conjunto de datos resulta demasiado grande por lo que al intentar ejecutarlo necesita un tiempo computacional altísimo. Debido a esto, se va a utilizar el método del codo. Para ello se debe encontrar la distancia media de cada uno de los puntos hasta el centróide del cluster. SKLEARN proporciona esta información mediante el atributo inertia, y mediante esto y utilizando la librería Matplolib para visualizar la evolución de los datos, se obtiene el resultado mostrado en la figura 3.
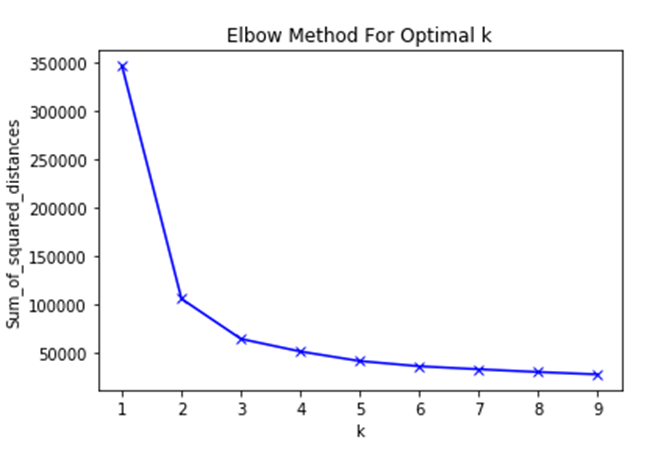
El método indica que el óptimo k se encuentra en 3 conjuntos. Con este dato se puede asignar a cada uno de los registros originales uno de estos tres clusters.
La tarea que queda pendiente para un próximo artículo es determinar el significado físico que tiene cada uno de los tres estados en los que se clasifican los datos, de forma que cada nuevo dato pasaría a formar parte de un estado y por tanto se podría establecer la situación de la máquina en cada instante. Por ejemplo, si se encontrase que los tres estados son Máquina en funcionamiento normal, Máquina funcionando de forma intermitente y Máquina parada, se podría llegar a determinar cómo evolucionan los datos entre un estado y otro, y por tanto se podría adoptar acciones preventivas cuando los datos indiquen una evolución negativa.
El proyecto está financiado por el IVACE con fondos FEDER, y en él participan las empresas KAMAX y FACTOR en las que se instalan los sistemas de captura de datos desarrollados.


Otras noticias publicadas del proyecto:
Si desea más información contacte con AIDIMME.
Visitas: 388

